


Latency is not a minor technical detail in conversational AI. It is the difference between a system that feels responsive and one that feels unreliable.
When responses take too long:
In voice environments, this effect compounds. Even small delays disrupt the natural rhythm of interaction, making conversations feel mechanical instead of fluid.
As conversational AI moves from pilots to production, latency has become one of the most important factors influencing performance, customer experience, and operational efficiency.
This guide explains how to optimize latency conversational AI systems end-to-end, with a focus on practical improvements that directly impact real-world performance across voice and chat.
To see how these systems operate in production environments, it helps to understand how modern AI contact centers are structured and deployed.
Latency refers to the time between a user input and a meaningful system response.
In simple terms:
Latency is the total time across that entire sequence.
This includes:
It is important to understand that users experience latency as a single delay, even though it is composed of multiple stages.
Voice interactions have fundamentally different expectations than chat.
In chat:
In voice:
Human conversation operates on tight timing loops. When those loops break, conversations feel unnatural.
This is why voice systems require stricter latency control than chat systems.
A common misconception is that latency is primarily a model problem.
In reality:
End-to-end latency includes:
Focusing only on model speed often leads to limited improvements. The most effective optimizations come from analyzing the full system.
This is why implementation architecture plays a critical role in performance, not just the underlying model.
To improve latency, it must first be broken down.
A typical conversational AI pipeline includes multiple stages, each contributing to the total response time.
The process begins before AI systems are even involved.
Delays can occur due to:
In distributed environments, network latency alone can introduce significant delays before processing begins.
This stage is often overlooked but can meaningfully impact total response time.
Speech recognition converts audio into text.
Latency at this stage depends on:
Batch processing requires the system to wait for the full utterance before transcription begins. This creates noticeable delays.
Streaming STT, on the other hand, processes audio incrementally, allowing downstream systems to begin earlier.
This shift alone can significantly reduce perceived latency.
Once text is available, the system must determine what the user wants.
This involves:
Each additional step adds processing time.
In complex systems:
While each step may seem small, the cumulative effect can be substantial.
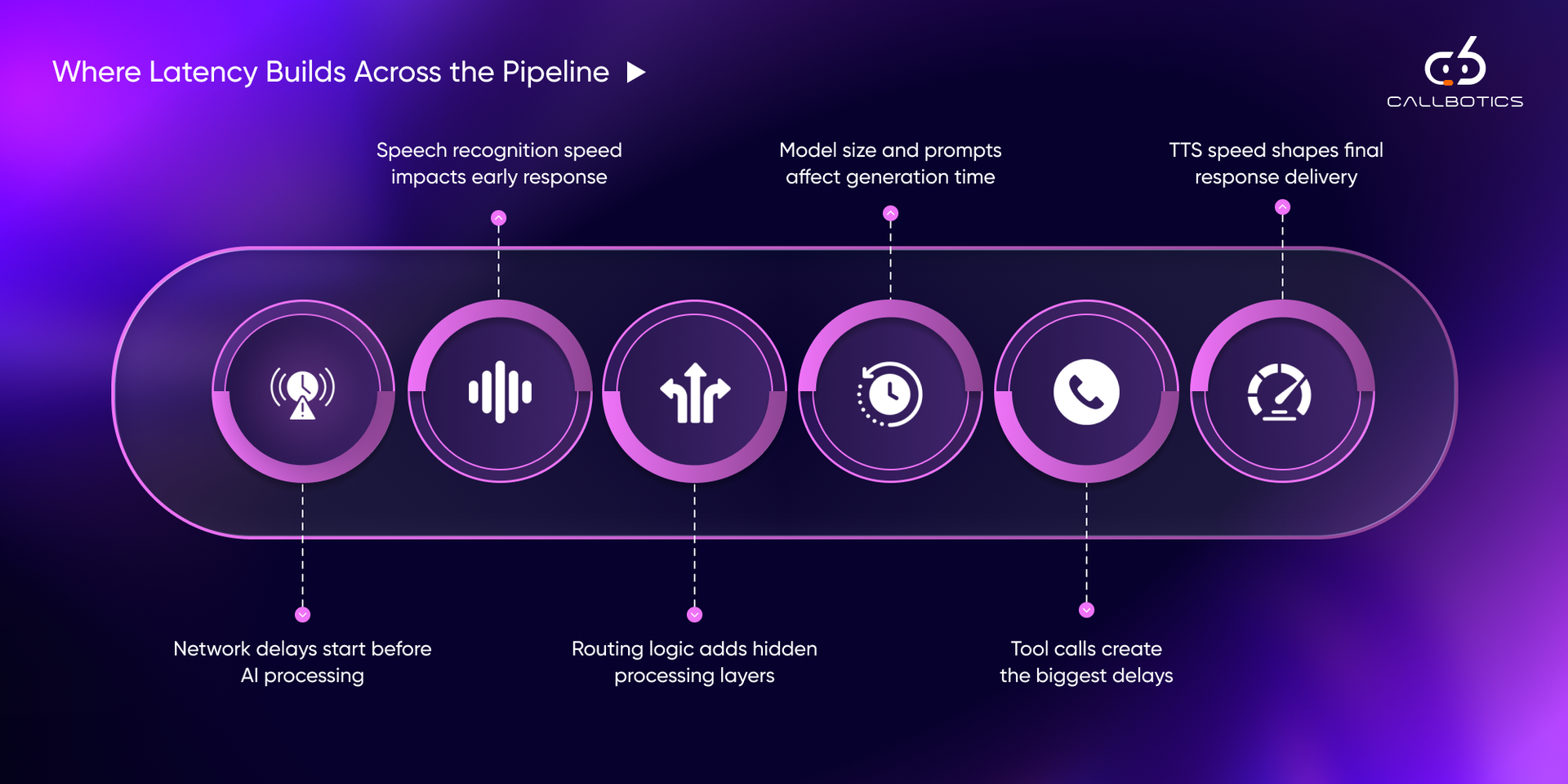
The core reasoning step involves generating a response.
Latency here depends on:
Long prompts increase:
Response generation also scales with output length.
While this stage is important, it is rarely the only bottleneck.
External integrations often introduce the largest delays.
These include:
Each call introduces:
When multiple tool calls occur sequentially, latency increases rapidly.
In many production systems, this stage contributes more to the delay than model inference.
For voice systems, responses must be converted back into audio.
Latency here depends on:
Batch TTS waits for the full response before playback begins.
Streaming TTS allows audio playback to start immediately as content is generated, improving perceived responsiveness.
Each stage may add milliseconds or seconds.
Individually, these delays may seem manageable.
Collectively, they determine whether the system feels:
Understanding this pipeline is the foundation for any meaningful optimization strategy.
Latency is not just a number. It is a perception.
Two systems with the same measured latency can feel completely different depending on how responses are delivered.
This is why benchmarks must be tied to human experience, not just system metrics.
In voice interactions, users expect timing that mirrors human conversation.
As a general guide:
The key is not just speed, but consistency.
A system that responds in 800 ms consistently will feel better than one that fluctuates between 200 ms and 2 seconds.
Unpredictability breaks conversational flow faster than steady delay.
Average latency is not enough.
Production systems should track:
Latency should also be measured by:
For example:
Without segmentation, averages hide the real problems.
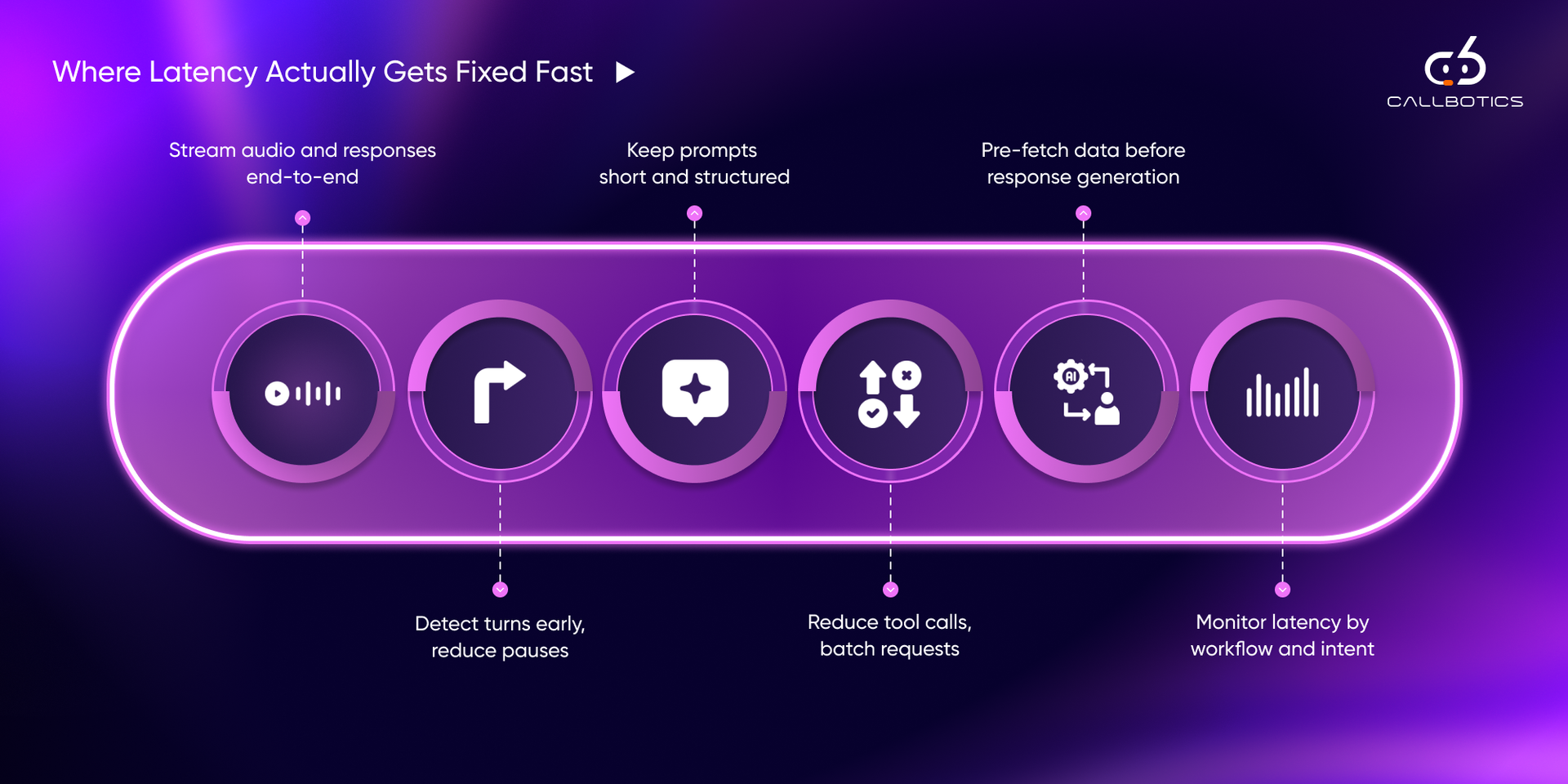
Improving latency is not about applying all fixes at once.
The most effective approach is:
The following strategies are ordered based on real-world impact.
Streaming speech recognition allows transcription to begin while the user is still speaking.
This enables:
Instead of waiting for silence, the system moves in parallel with the user.
This reduces perceived latency significantly.
Turn-taking is critical in voice systems.
Without accurate end-of-turn detection:
VAD helps detect when a user has finished speaking, allowing faster response initiation.
Small improvements here can dramatically improve conversational flow.
Instead of waiting for a complete response, token streaming delivers output incrementally.
Benefits:
Even if total generation time remains the same, early partial output improves experience.
Large prompts increase:
Effective prompts:
Reducing prompt size is one of the simplest ways to improve response speed.
Not every query requires model inference.
Frequently repeated queries such as:
can be cached and served instantly.
This reduces:
A two-stage approach improves both speed and quality.
Step 1:
Step 2:
This ensures:
Each external call introduces a delay.
Instead of:
Use:
Reducing dependency chains is critical for latency optimization.
Once intent is detected, systems can prepare data proactively.
Examples:
This removes waiting time during response generation.
Geographic distance matters.
Latency increases when:
Optimizing:
can significantly reduce response times.
Text-to-speech can become a bottleneck.
Optimizations include:
This ensures playback begins immediately rather than waiting for full synthesis.
When unavoidable delays occur, conversational cues can maintain engagement.
Examples:
These should be:
The goal is not to mask latency, but to maintain conversational continuity.
Not all workflows are equal.
Some flows:
Prioritizing high-impact workflows ensures faster improvements.
Ultimately, latency optimization contributes directly to higher first call resolution by enabling faster and more accurate interactions.
The most effective systems do not just reduce latency.
They manage how latency is experienced.
This includes:
In many cases, improving perceived latency delivers greater impact than reducing actual processing time.
Latency issues rarely come from a single decision. They accumulate from small design choices across the system.
The most common patterns include:
Adding more context than necessary increases processing time without improving outcomes proportionally.
Chained API calls introduce compounding delays, especially when dependent on each other.
Repeated queries unnecessarily hit the model or backend systems instead of returning instantly.
Batch processing at any stage creates visible pauses. This includes STT, LLM responses, and TTS.
External systems deployed in different regions or with poor response times become hidden bottlenecks.
Average latency hides the real experience. Tail latency (p95 and above) is what defines perceived reliability.
These issues are not isolated. They often appear together, reinforcing each other and degrading the overall experience.
Before deploying or optimizing a system, structured testing is essential.
Latency should be tested under stress conditions:
Systems that perform well under ideal conditions may fail under real usage.
User environments vary significantly:
Testing only in controlled environments leads to misleading results.
Focus on:
The goal is to ensure consistency, not just peak performance.
Latency optimization is not achieved through isolated improvements. It requires coordination across the full interaction lifecycle.
CallBotics approaches this as a system problem, aligning workflow design, model execution, and operational visibility to reduce delays while maintaining conversational quality. This approach is informed by over 18+ years of experience in the contact center industry, where real-world constraints such as call volume spikes, routing inefficiencies, and agent workflows directly impact response times.
At a foundational level, the platform focuses on:
This ensures that conversations feel responsive without compromising depth or accuracy.
CallBotics integrates latency optimization into core platform capabilities rather than treating it as a separate layer.
Every interaction is evaluated for correctness, compliance, and policy adherence.
Detects emotional tone, escalation triggers, and shifts during conversations.
Organizations can track metrics such as conversion rates, outcomes, and handling patterns.
Identifies at-risk customers based on behavior and sentiment signals.
Supervisors can listen in real time, provide guidance, or intervene when necessary.
Measures delays across the interaction pipeline to detect performance bottlenecks.
Supports large enterprises managing multiple teams or clients.
These capabilities create a feedback loop where:
This aligns directly with the earlier principle: latency must be managed at the system level, not just the model level.
In production environments:
A platform that combines:
It is better positioned to maintain consistent performance across these variables.
Latency in conversational AI is not a single variable to optimize. It is the result of multiple interconnected systems working together.
The most effective improvements come from:
Organizations that treat latency as a system-level concern can:
As conversational AI continues to scale across voice and chat, latency will increasingly define not just performance, but trust.

Urza Dey (She/They) is a content/copywriter who has been working in the industry for over 5 years now. They have strategized content for multiple brands in marketing, B2B SaaS, HealthTech, EdTech, and more. They like reading, metal music, watching horror films, and talking about magical occult practices.
See how enterprises automate calls, reduce handle time, and improve CX with CallBotics.
CallBotics is an enterprise-ready conversational AI platform, built on 18+ years of contact center leadership experience and designed to deliver structured resolution, stronger customer experience, and measurable performance.




